QuestDB Brain Dump
Disclaimer: Views expressed below are my own and do not represent my employer.
QuestDB is an open-source time-series database built from the ground up for speed, efficiency, and ease of use. It is heavily used by firms in the Financial sector, IoT / Industrial applications, and Crypto [1]. Some of the prominent customers include B3 (Latin America’s largest stock exchange), Airbus, Airtel and XRP. In the early years of the company, it seems that they were focused exclusively on Time Series problems [2]. However, they have recently been venturing into the OLAP space [3]. One reason for this could be that OLAP systems have proven to be quite versatile: most modern OLAP vendors support reading data directly from object stores, vector search, upserts, running timeseries queries via PromQL, distributed joins, high throughput ingestion with the usual low-latency queries, and more recently, the ability to read data stored in Iceberg. With all of these features, it is a hard market for QuestDB to venture into, with stiff competition from companies like ClickHouse, StarRocks, StarTree, etc. [4]. Regardless, QuestDB is quite popular and I have only seen positive sentiment expressed towards the company, which is a good signal.
QuestDB originally started as a side project by the current CTO Vlad Ilyushenko all the way back in 2013, when “he was building trading systems for a financial services company and was frustrated by the performance limitations of the databases available at the time” [5]. QuestDB the company was founded in 2019, with their seed round conducted by YC in 2020.
Technology Overview
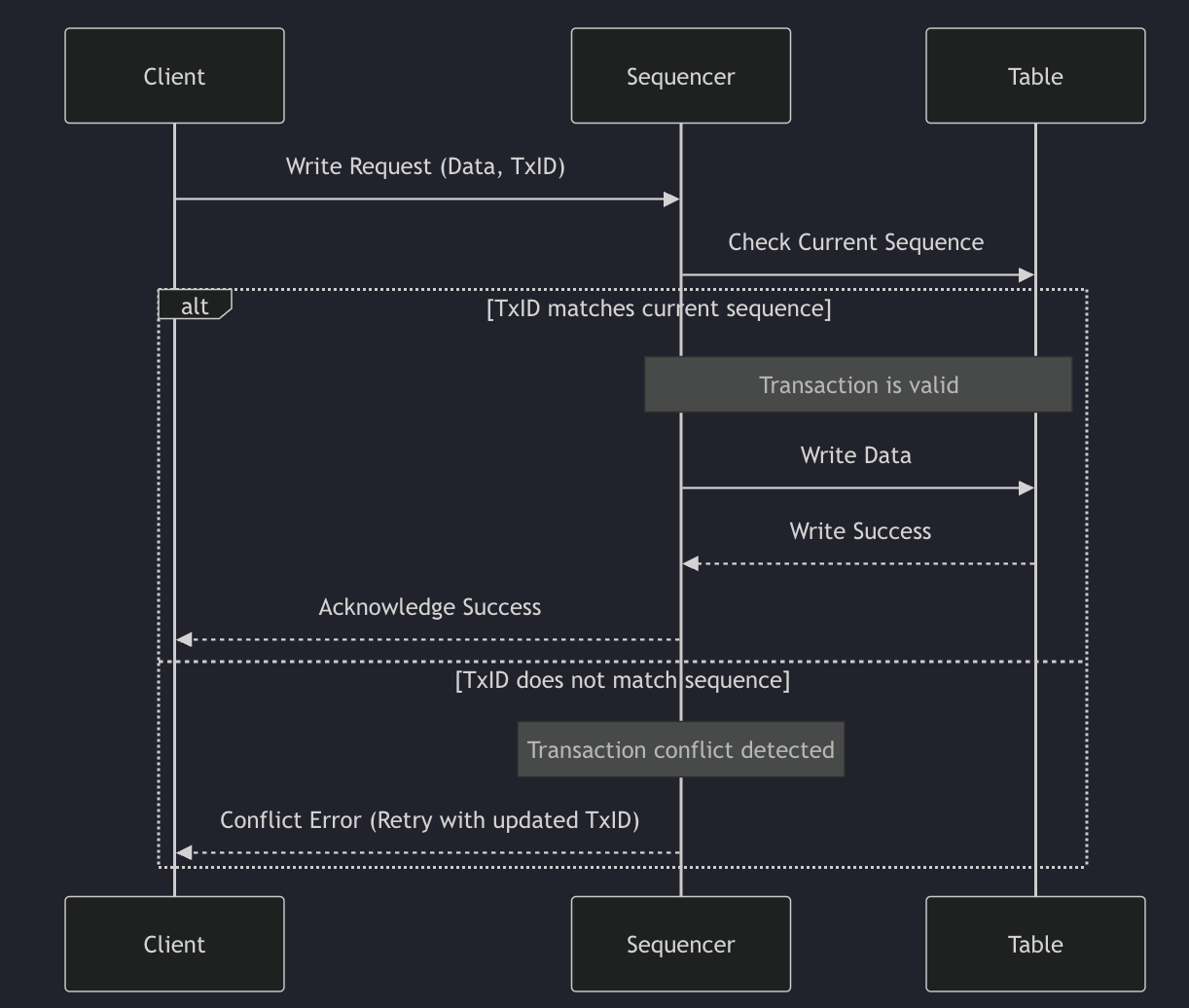
Figure-1: Multi-primary writes design. Source: QuestDB [6]
There’s not a lot of information available online about this, but I suppose the most straight-forward mode of running the open-source version of QuestDB would be to run it with a single-node setup in a Cloud VM backed by a persistent volume. Backup and Restore is available in the Open-Source version but high-availability features like replicas are limited to the Enterprise edition. Their enterprise version supports a cluster based setup with support for Multi-primary writes coming soon [5]. The design of their multi-primary ingestion is quite interesting: each client is expected to get a unique and auto-incrementing transaction ID from a Foundation DB cluster, which also serves as a common metadata storage.
One can use QuestDB client libraries for ingestion, and QuestDB also accepts InfluxDB Line Protocol (ILP) over a socket connection. The query language is SQL and largely compliant with PostgreSQL, with some custom syntax added to facilitate time-series analysis like “SAMPLE BY”.
On the implementation side, QuestDB uses an unorthodox style of Java (reminiscent of Chronicle), with a lot of the performance critical code written in C and bridged through the JNI. The Java code heavily relies on Unsafe and manual memory management to avoid GC overhead. The code is zero dependency and you can even run QuestDB in Embedded mode in your Java application. QuestDB also leverages several advanced low-level optimizations like SIMD, IOUring, JIT compiled filters, etc.
Storage Model

Figure-2: QuestDB data layout on disk. Source: Javier Ramirez at Data LDN 2024. [8]
Data in a table is partitioned by time with the lowest allowed granularity being HOUR. Within a partition, each column has its own file. Variable length columns (string and binary) actually have two files: one is the data file and the other is the offsets file. Moreover, within each partition data is sorted by the “Designated Timestamp” column.
Though there has been mention of not relying on Indexes much in some of their talks, their “SYMBOL” type is dictionary encoded and uses bitmap inverted indices. They also store data in each partition in sorted timestamp order.
Deduplication within a short time period is supported and you can configure a set of columns as your Upsert keys. For instance, if there’s a scenario where a bunch of servers are emitting system metrics every second, the Upsert key might be epochSeconds and the serverId. Out of order (O3) writes are also supported in two ways. Roughly speaking, if the out of order events are for very recent data, QuestDB will resort the tail of the current file that’s being appended to, or sort the data when it is applying the WAL itself. If the O3 events are quite far apart, it may trigger a partition split to reduce write amplification.
A WAL is created for each table and connection. Moreover, across all WALs for a table, a Sequencer ensures that the transaction id is a unique, auto-incrementing number. This ensures that all the readers always get a consistent view of data. WALs are also helpful for resolving O3 writes and supporting deduplication.
QuestDB has a Checkpoint mode which can be used to take backups. The process described in their Wiki seems to suggest that this can cause some downtime and is a somewhat manual process. It was kind of a surprise to me that this is not something that it can do automatically in the background (I suppose the Enterprise version may do it).
QuestDB also takes snapshots which can be helpful to continue to serve queries while data is being resorted due to O3 writes. Once the data rewrite job is done, the snapshot pointer is atomically moved to the new data copy.
Query Overview
QuestDB supports PostgreSQL compliant SQL, with some custom extensions to facilitate time-series analysis. Notably, PromQL is not supported, but it does have its own Grafana and Superset connector with a Query Builder utility similar to the Prometheus connector. Joins, including time-oriented joins like ASOF joins, are also supported.
High query performance is achieved by:
- Allocating nearly everything off-heap via Unsafe and managing memory manually, minimizing GC impact.
- Using C++ and SIMD. They use JNI to bridge between Java and C/C++. C++ is used for compute intensive operations such as those involved in deduplication, bitmap indices, aggregation functions on vectors of data, etc. Using Unsafe and tracking memory explicitly using
longaddresses makes this quite easy. - Custom data structures for nearly everything: from type-specific List implementations that don’t have bounds check overhead, to multiple flavors of open-addressed hash tables.
- JIT compiled filters, though this only works on x86.
- Leveraging inverted indexes and in-memory caching for Symbol type, designated timestamp sort order and time partitioning.
- Miscellaneous optimizations like SQL Rewrites for certain query patterns (common in OLAP systems), SWAR optimization for LIKE computation, etc.
Interestingly, they primarily rely on Mmap for I/O. They do use IOUring, but it seems limited to their Copy Task only as of now. IOUring again is implemented in C and bridged through JNI.
Query Execution Model
The query execution model is async and message driven. The inter-thread messaging system is built from scratch, seems similar to LMAX’s Disruptor [13], and is used for nearly everything: from ingestion to query execution.
Query processing is done in chunks called PageFrames.
The query owner thread uses a RecordCursoryFactory that returns a RecordCursor that can be used to
iterate over the result tuples. The rough sequence of events that involve query execution are:
- The
RecordCursorFactoryreturns aPageFrameSequence. Notably,RecordCursorFactoryobjects are cached for the similar query strings (this is their form of plan caching from what I can understand). Each cursor factory has its own re-usedPageFrameSequence, which is cleared on completion of the query. - The
PageFrameSequenceis first prepared for dispatch, which involves computing the page frames for the current query and initializing off-heap memory addresses for the corresponding page frames to be used for table scans (seeTablePageFrameCursor). There are two types of page frames at the moment: Parquet page frames and QDB’s Native page frame formats. - The query owner thread calls
PageFrameSequence#next(). On first call, this will dispatch all the page frames and publish them to the reduce task queue. This task queue is subscribed by theWorkerthreads. Results are published to the “collect” queues. - Calls to
PageFrameSequence#next()can return processed page frames pushed to the collect queue by the worker threads, as and when they are available. - The thread that calls
PageFrameSequence#next()can also steal tasks and run them within that thread, if the collect queue is empty and tasks have already been dispatched.
Page Frames are created hierarchically: tables are divided into Partition Frames, and each Partition Frame in turn creates Page Frames.
There’s a lot more to unpack around their query execution model, and it warrants a blog post of its own.
Notable Optimizations
There’s a ton of really cool optimizations QuestDB folks have done. Calling out some of the notable/cool ones below.
VarChar Prefix Header for Fast Comparisons
They store an approx. 6 byte prefix of a given UTF-8 sequence, which is used for speeding up comparisons.
You can refer to Utf8s#equals and EqVarcharFunctionFactory to see how this is wired in.
This might remind readers of the “German Strings” design originally proposed in the Umbra paper.
Optimized Utf-8 VarChars
Processing of VarChars is largely done through Utf8Sequence, which has both on-heap and direct memory implementations.
From what I can tell, the advantages of using Utf8Sequence are:
- Their varchar type is stored in UTF-8 on disk. Using a custom implementation allows them to directly store a reference to the memory mapped address of the string, without any copies.
- Java’s String is either ASCII or UTF-16, so
Utf8Sequenceserves as their general varchar representation that doesn’t need to be transcoded at any time during query execution. - For ingestion, their guideline is to use UTF-8 encoding for strings. This means that the encoding stays the same at ingestion, storage, and query processing.
I also see them taking advantage of the direct byte[] access with Utf8Sequence to enable very bespoke
optimizations like using SWAR sorcery for the LIKE operator, when the patterns are <= 8 bytes by leveraging . The SWAR optimization was specifically done to improve their ClickBench numbers [7].
Custom Data Structures Including Direct Memory Versions
They have custom implementations of a lot of primitive data structures like IntList, to incorporate context specific optimizations (avoiding unnecessary bounds check in this case).
They also have a lot of “Direct” memory backed data structures, which are quite helpful in moving across the JNI
boundary. For instance, the DirectLongList doesn’t store the buffer on-heap, but instead only stores a long address
and the list metadata. A direct application of this can be seen in
AsyncJitFilteredRecordCursorFactory, where the execution
result of the JIT compiled filter is a memory address, that is upserted to the current task’s filteredRows reference.
JIT Compiled Filters
On x86 systems, QuestDB can use JIT compilation to compile filters into optimized machine code with a loop that iterates over the records and executes the filter. The frontend is implemented in Java, and the backend is implemented in C++ and uses the asmjit library.
The filter is first serialized to an intermediate representation in Java land. The serialization filter is stored off-heap, and the memory address of the IR is passed to C++ which generates the assembly code, and returns a memory address pointing to the compiled filter.
Then each time a frame needs to be evaluated, the off-heap data address is passed to the C++ backend, along with the memory address of the compiled filter. The generated filter can also leverage SIMD.
It must be noted that they didn’t rely on LLVM and went with their own IR and JIT compiler. It reminds me of how folks behind Umbra had noted that implementing their own JIT Compiler had allowed them to build a really fast jit compiler, capable of generating code for 2k+ table joins in under 30ms. I wonder how QuestDB’s custom implementation compares with the LLVM based approach.
Hash Table Optimizations
They have multiple flavors of hash-tables available, and many of them store data off-heap. They also have some maps dedicated
for specific key or value types, like LongLongHashMap, UnorderedVarcharMap, etc.
They mostly use Open Addressed Hash Tables with Linear Probing. They have also fine-tuned their map implementations:
- They have used a lower load factor (~0.4) for some of their HashMaps. For context, Java mostly uses 0.75 as the default in most of their hash-map implementations. Having a lower load factor means that they allocate slightly more memory, but the individual query latencies can improve quite a bit for higher cardinality group-by scenarios (there’s more nuance to this per se).
- They use
longhash-codes which can particularly be helpful for scenarios when the number of group-by keys can be really high and comparable to int-max. pr#4348 - They also have a hash-table implementation in C, nick-named “Rosti”. It is used for vectorized aggregation functions, since vectorization allows for running aggregations in batches, which can offset the cost of traveling across the JNI boundary.
What’s Cooking
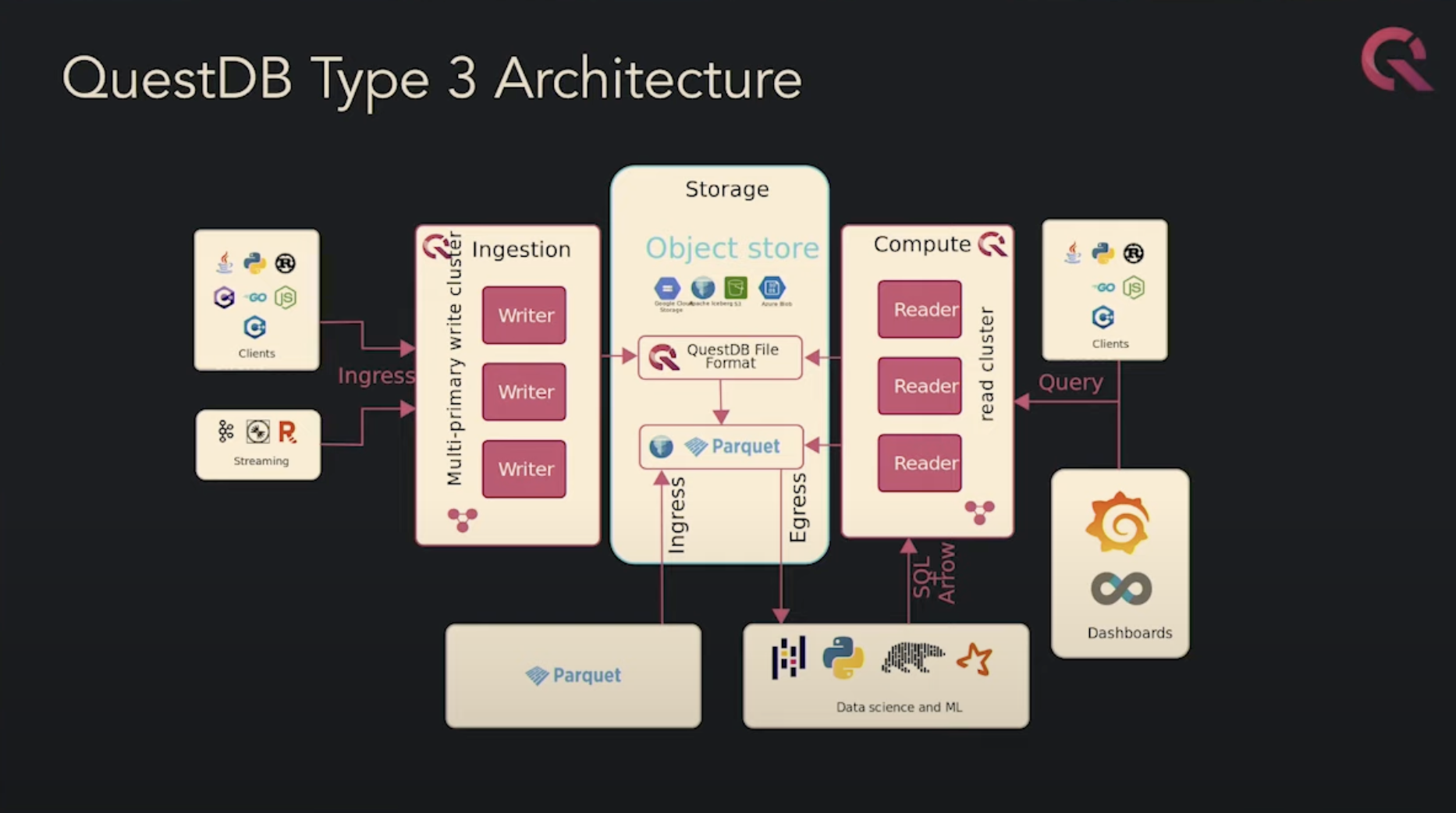
Figure-3: Type-3 architecture, as presented by Javier Ramirez at his Big Data LDN talk in 2024 [8]
They are moving to what they call a Type-3 architecture. With it, QuestDB will be able to:
- Read data in native QuestDB format from Object Storage.
- Read data in Parquet or Iceberg format from Object Storage.
- Separate compute and storage, and compute/compute (e.g. u)
This is pretty similar to what other OLAP vendors like ClickHouse, StarTree, InfluxDB, etc. have been doing.
Notably, their type-3 architecture seems to be largely relying on a Rust based implementation. They have implemented their own Parquet reader in Rust too, which they claim is 10-20x faster than the official Parquet Rust crate. The reader can’t be used to read data directly though: it is designed to read compressed Parquet pages and decompress them to an in-memory format of your choice. They recommend combining their implementation with arrow2 to actually read data.
References
- QuestDB Customers
- BigData LDN Talk by Javier Ramirez (2022): YT Link
- Introducing the Type-3 Architecture by Javier Ramirez at Conf42 IoT 2024. YT Link
- HackerNews discussion on QuestDB and ClickHouse. link
- TechCrunch article on QuestDB Seed Round: link.
- Multi-primary ingestion docs
- p99 Conf by Andrei Pechkurov YT Link.
- Future of Fast Databases by Javier Ramirez YT Link
- Ingesting a million time-series per second on a single instance YT Link
- QuestDB storage model docs
- Importing 300k rows with IO Uring. link
- Accelerating QuestDB by Javier Ramirez at Berlin Buzzwords 2025 YT Link
- How we built inter-thread messaging from scratch blog
This is a custom-built theme for Jekyll. Please report any issues on GitHub.