InfluxDB Brain Dump
Disclaimer: Views expressed below are my own and do not represent my employer.
Background
InfluxDB is one of the most popular time-series and realtime analytics databases out there, and is part of the InfluxData Platform. It has been around since 2013, but has gone through a couple of major version upgrades in that time. InfluxDB 3.0, the latest version, is not open-source, though some of its core code is. There are many different variants of even the latest version of InfluxDB: InfluxDB Edge, InfluxDB Community, etc. It is slightly hard to wrap your mind around all of them, but if you are interested you can check out this post on InfluxData.
Ignoring the kerfuffle around the version upgrades, folks at InfluxDB have done a bunch of really cool work especially with DataFusion, and the rest of this blog focuses on the same.
Overview
Written in Rust, InfluxDB is built on the FDAP Stack: Apache Flight, Apache Data Fusion, Apache Arrow, and Apache Parquet. Some of the characteristics that define most of the InfluxDB use-cases are: 1) Schema on Write 2) High Rate of Denormalized Ingestion 3) Most of the Business Value lies in the most recent data 4) Time based retention configured by users.
At a high-level, their architecture is as shown in Figure-1. The ingester ingests data from user sources and stores it in the Object Store. The compactor merges the flushed Parquet files to avoid the small files problem, improve compression, and improve query performance. Notably, the querier queries both the Ingester and the Object Store.
Catalog is the metadata store, and Garbage Collector deletes “soft deleted files”, which include files deletes by the compactors, out of retention files, and files deleted through a delete command.
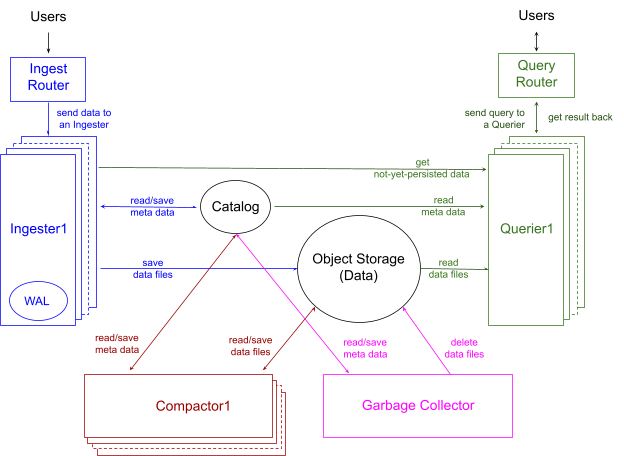
Figure-1: InfluxDB 3.0 System Architecture. Source: InfluxData
Data Ingestion

Figure-2: InfluxDB Line Protocol. Source: InfluxData
Data ingesters accept data in the InfluxDB Line Protocol shown in Figure-2. The data is buffered in memory in Arrow Compatible format until a size threshold or time threshold (10-15 minutes) is reached. The WAL is flushed every second or so as a new file to Object Store.
The data is flushed as sorted Parquet files, and since the buffered data is Arrow Compatible, it can be fed into a DataFusion plan for Sort and Dedup. The Parquet file is written using the parquet-rs writer.
Since the goal is to support realtime analytics and time-series queries, and the fact that the data is flushed as Parquet only every few minutes, the querier nodes have to hit ingesters for querying the unbuffered data, and that’s where buffering in Arrow compatible format is helpful.
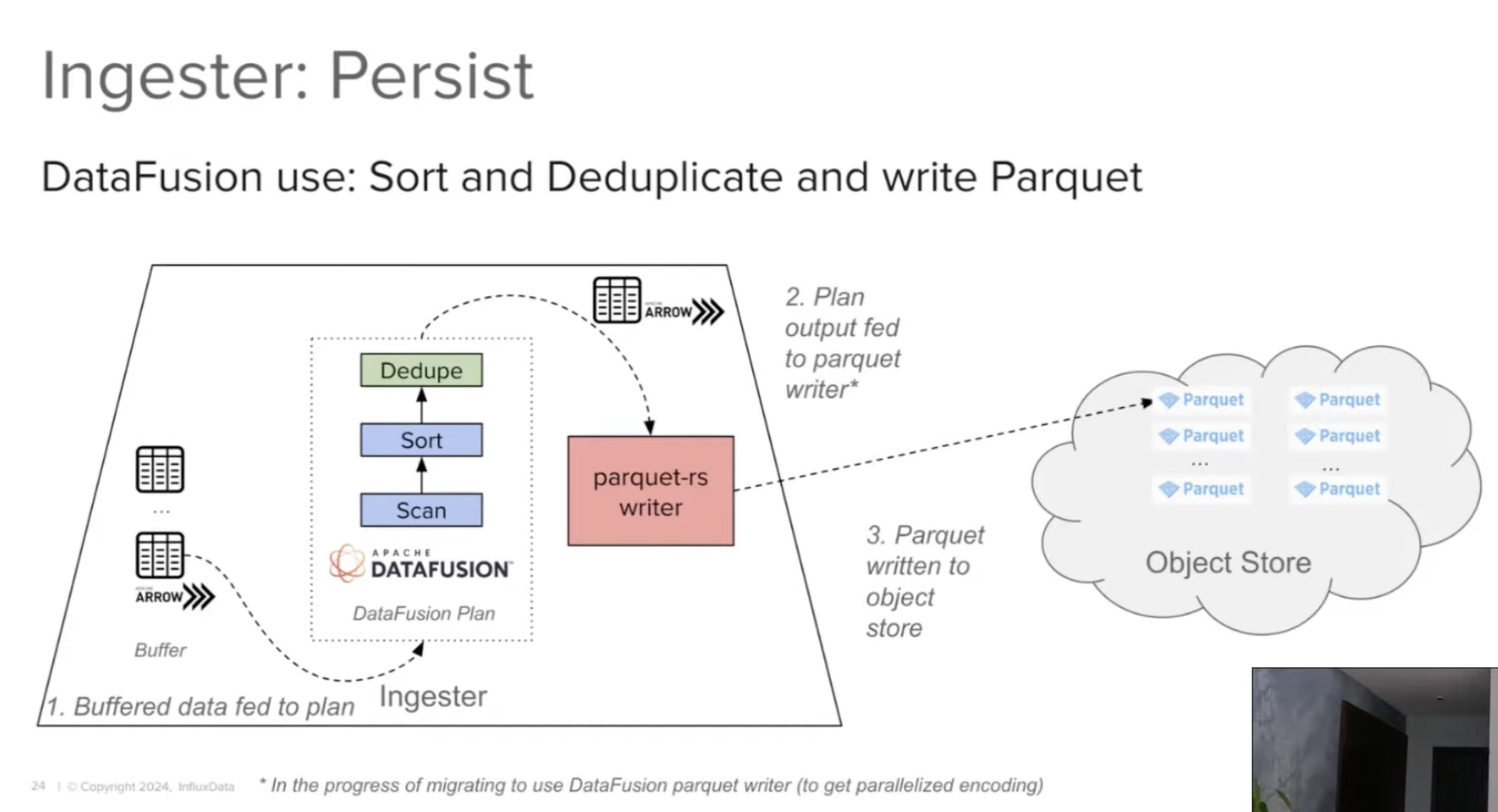
Figure-3: InfluxDB Ingester Overall Flow. Source: CMU Database Group
To optimize queries on the buffered data, they track min/max values of time and the user tag partitions, and leverage DataFusion’s PruningPredicate to limit the amount of data returned to the querier.
Data Compaction
As mentioned before, the role of compaction is to avoid the small files problem and improve compression and query performance. One of the interesting parts of this is that the compaction job also uses DataFusion to read the Parquet files and merge/dedup them. The files are written back again using the parquet-rs writer, though they mentioned that they are in the process of moving to DataFusion for writing the Parquet files to Object Storage for both the Data Compaction job and the Ingester.
Query Language
In their recent CMU DB Talk, they called out that “SQL is kind of a pain to work with time series” use-cases. In Influx 1, they had introduced InfluxQL which looks like the following. It went through some semantic changes with Influx 2.0, but seems like InfluxQL is still supported with Influx 3.0 and here to stay.
SELECT
MEAN(usage_idle),
MEAN(bytes_free)
FROM cpu, disk
WHERE time > now() - 1h
GROUP BY TIME(10s)
FILL(linear)
In Influx 2, they had also started supporting a new scripting language called Flux. Flux looks like the following, and it even allowed running complex logic such as making remote network calls from within the database.

Figure-4: FluxQL. Source: InfluxData
In InfluxDB 3.0, they dropped support for Flux altogether and instead added support for SQL.
Querier
InfluxDB supports multiple query frontends: SQL, InfluxQL, and a “Storage gRPC Frontend”. The querier accepts queries in the FlightSQL Protocol via a gRPC endpoint, which forwards the query to the Query Planner.
The Query Planner sends a request to the Catalog to get the information about the location of the relevant partitions involved in the query. It also sends a request to the Ingester to request the latest unbuffered data required for the query.
Performance of the system would heavily rely on the number of Parquet files that need to be analyzed, and hence they do multiple levels of pruning. First is the time based pruning of the Parquet files which is powered by a local Metadata cache. This works nicely because the files for a partition represent non-decreasing time buckets, and hence it’s possible to narrow down to a range of files by just checking the file’s min/max time values. This is done even before the DataFusion Query Planner is called.
Additionally, they leverage DataFusion’s PruningPredicate and TableProvider API to implement partition + file pruning. Influx allows each table to be configured with custom partitioning rules, where users can use time and tags to partition their data (ref). So if a query contains a filter on the partitioned column, then you will be able to prune files even further. I think they also track non-partition column’s min/max values, and use the PruningPredicate to filter out files even further, but I am not sure about this.
The Querier also caches data locally from the Object Store, which might be expected.
Custom SQL Gapfill
They added a custom Gapfill function called date_bin_gapfill which looks similar to Timescale’s time_bucket_gapfill function. From an execution point of view, they transform the query plan
to add a custom plan node after the GroupBy plan node which inserts empty rows as required.

Figure-5: date_bin_gapfill example. Source: InfluxData
Notable Optimizations
Now that the Overview is out of the way, I wanted to talk about some of the cool optimizations they have implemented and incorporated.
StringView
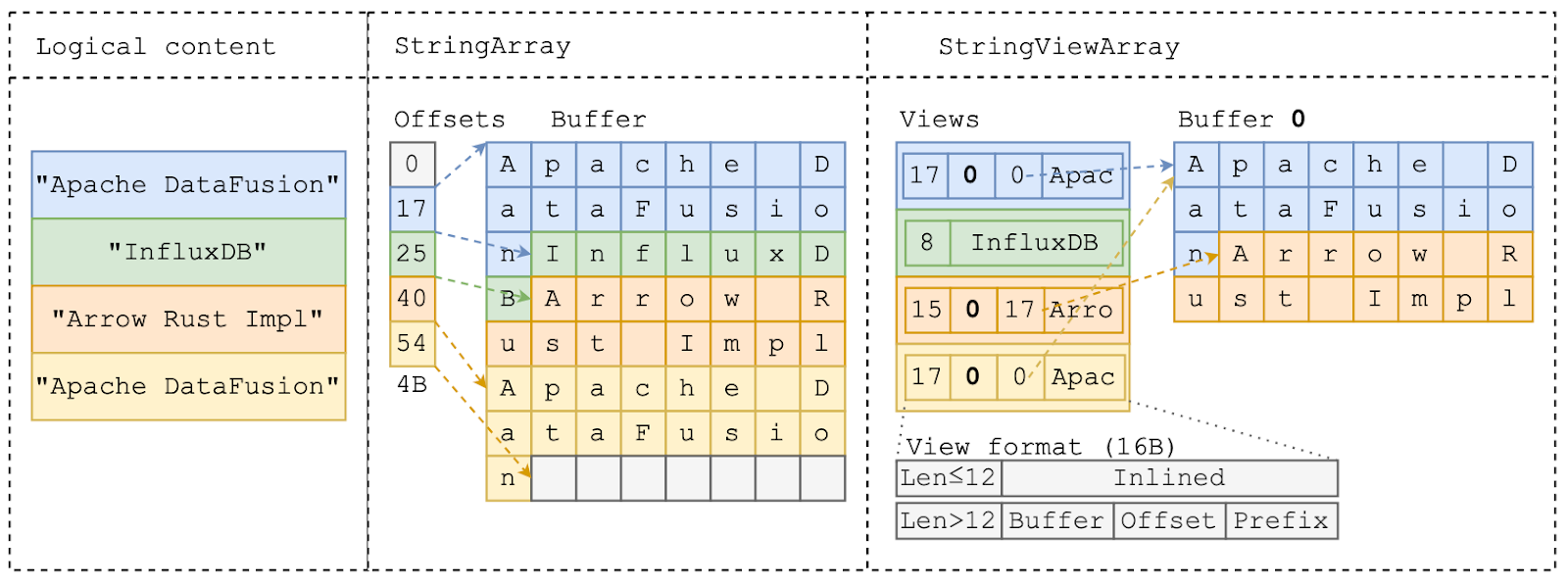
Figure-6: StringView diagram from one of the InfluxDB Blogs. Source: InfluxData.
Inlining prefixes in String Headers was originally introduced in the Umbra paper by the folks at TUM. It has become a very popular idea since then, having been adopted by Velox, DataFusion, Arrow, etc. This is also often referred to as “German Strings” given the TUM origins.
The Apache Arrow version of this, called StringView is shown in Figure-6. Instead of the regular approach of storing var-length strings using a single offsets array, the StringView approach stores a “Views” array which has the same length as the number of strings, and each element is 16 bytes.
If the string length is less than 12, then the first 4 bytes store the string length and the remaining 12 bytes store the actual string. When the string is longer than 12 bytes, then the actual contents of the string are stored in a separate buffer, and you only store a 4-byte prefix along with coordinates of the actual contents of the string.
The core idea here is that you can optimize string comparisons and potentially reduce memory allocations if your filters are even moderately selective. Though the idea is simple, a straightforward implementation is likely going to be worse than status quo in most of the cases.
InfluxData folks have documented their journey of adopting StringView and optimizing it iteratively in these blogs: 1, 2. Some of the interesting callouts from it are:
- UTF-8 validation, which is run when a byte sequence is loaded as a string, had quickly become a bottleneck. This is because the StringView implementation reuses the decoded Parquet page, which consists of both strings and integers. To load each string would mean running the UTF-8 validation separately, whereas their existing approach relied on a concatenation of strings, where only the concatenated string buffer needed to be UTF-8 validated. To address this, they relied on the fact that 99% of the strings in a real world scenario are <128 characters, in which case you could simply encode the string lengths using ASCII. (ref: pvldb-vol17)
- They ran into subtle Rust language semantics which were introducing implicit copies. I am no Rust user or expert, so I’ll simply refer you to this issue that was linked in the part-1 of their StringView blog.
- They had found that their implementation was slower for short strings than the longer ones. They had to use godbolt to look at the generated CPU instructions, and they found that since their code for handling the longer strings had the prefix length known at compile-time, it was generating CPU load instructions. Whereas the code to handle short strings was using ptr::copy_non_overlapping. To handle this, they are generating code for each of the prefix lengths between 4-12.
- Integrating StringView into all String operations takes a considerable amount of effort.
- After running the filters, DataFusion will usually create a new array with only the matched values, and traditionally this would require another copy. With the StringView approach, all one may need after a filter operation is to create a new StringView array that points to the offsets in the old buffer.
- However, the above also has a downside that you will hold on to excess memory from the old buffers for longer, especially for highly selective filters. To handle that, they implemented a GC mechanism which restructures the buffers if the cardinality is predicted to drop reasonably (refer: datafusion/11587).
Parquet Optimizations
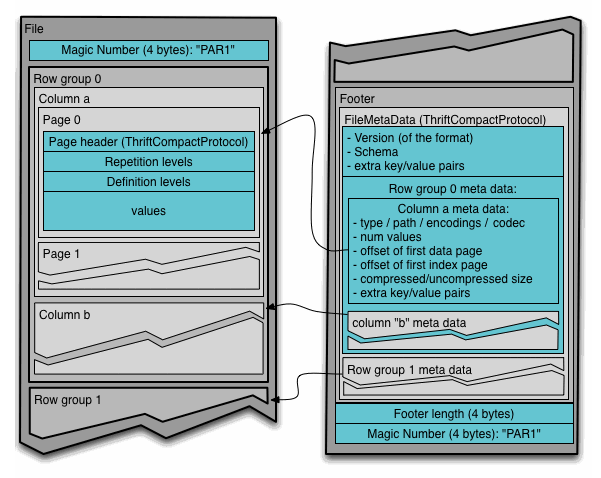
Figure-7: Parquet Layout. Source: Apache Parquet.
DataFusion uses a ton of Parquet optimizations, most of which are documented in this blog. Most of the optimizations like Projection Pushdown, Predicate Pushdown, Bloom Filters, etc. are quite common in Analytical Databases. The ones I found interesting are summarized below:
- Decoding entire RowGroups in Parquet can be impractical for most cases since the uncompressed data can quickly take a lot of memory. Instead, it is better to produce row batches of configurable sizes. Though for Parquet this can be hard, especially because column chunks in a row-group can have different sizes for different columns, presumably because length of the columns can vary based on the type and data.
- Dictionary preservation, which refers to storing Dictionary IDs (Integers) for as long as possible, becomes hard because the dictionary changes across row-groups. Moreover, some columns may be partly dictionary encoded in Parquet, further complicating the implementation.
- For scenarios with multiple filters, say
A > 35 AND B = 'F', the filters are run sequentially, and they enable incremental Page pruning. e.g. ifA > 35means that we only need to read row-numbers> 200, then that information can be used to prune the pages of columnBwhen evaluatingB = 'F'. - They leverage Rust Parquet Reader’s AsyncFileReader, which hooks in neatly into the Tokio Runtime, and allows them to read and process multiple files in parallel, helping maximize CPU and I/O Utilization and reduce query latencies.
Dynamically Skipping Partial Aggregations
Query engines usually run aggregations in two phases: the first phase does a “local aggregation”, often called “Partial Aggregation”, and the second phase completes the aggregation, and is commonly called the “Full Aggregation”. This is usually done to reduce the amount of data produced by a stream as soon as possible (among other reasons).
However there are some scenarios where running a Partial Aggregation step doesn’t make a lot of sense. Example: when the number of input-rows is very close to the number of distinct groups in the query.
To optimize this, their approach is to skip the Partial Aggregation when it is not effective. They do this dynamically and their approach is (ref: datafusion/11627):
- For the first few input rows, they run the partial aggregation as is. This is the probe threshold and by default set to 100k.
- If the ratio:
number of distinct groups / number of input rowsexceeds a configured threshold, then switch to full aggregation. This is set to 0.8 by default.
Avoiding Redundant Copies in Multi-Column Group By
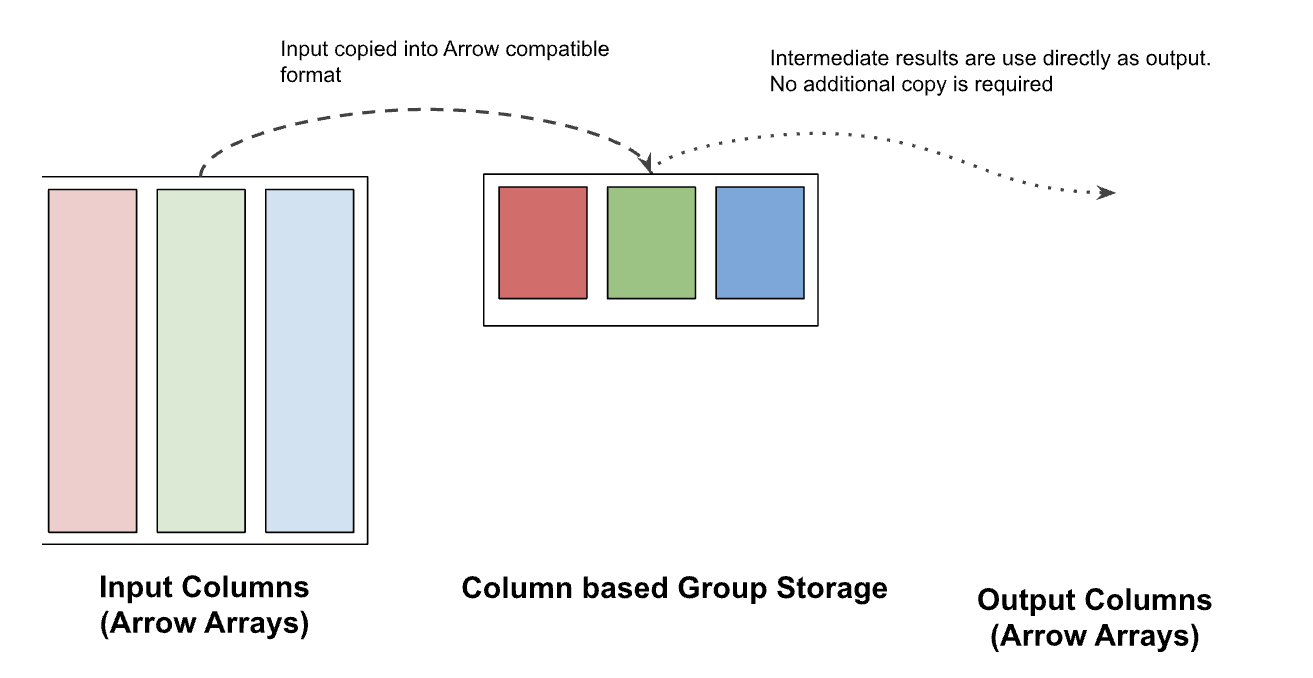
Figure-8: Multi-Column Group By in DataFusion 43.0. Taken from InfluxDB.
An intuitive approach to implementing multi-column group-by in a query engine where the output should be Columnar would be to store the multi-column groups during the GroupBy in a row-based storage, and then converting them back to a columnar format at the end. However, this requires copying the groups twice, which can be a overhead for scenarios with a high number of grouping sets.
In DataFusion 43.0, they added support for storing the intermediate results directly
into Arrow compatible format. You can refer to the column_wise.rs file in
datafusion/12269 to understand some of the
implementation details.
In 44.0, they even added vectorized support for append and compare in multi-column group-by queries, likely yielding another ~10% improvement (ref: datafusion/12996).
Progressive Evaluation
This optimization caters to queries which have the clause: ORDER BY time DESC/ASC LIMIT n.
In other words, the queries are looking for the most recent data up to a certain limit.
If a query engine is agnostic of the fact that the time values are largely in a given order
across a set of files, it would have a plan which looks like the following. i.e. you would
usually rely on a simple Sort Merge:
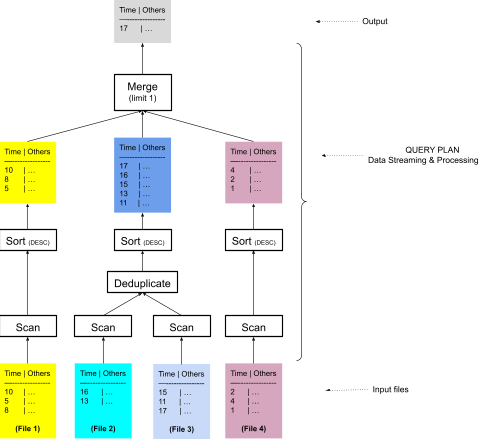
Figure-9: Sort Merge based plan to answer the last N values query. The deduplicate step is required because consecutive files may have overlapping time values. Source: InfluxDB.
The reason this is inefficient is because you have to run the Operator chain for all of the files, even if you only need to read a very small subset of them given the time order and the limit in the query.
A better way is to read the files in time-order and return early once an exit condition is
reached. To achieve this, they added a ProgressiveEval operator which processes the streams
in time-order. My understanding is that they process one stream at a time, and schedule a
pre-fetch for the next stream in case the current stream is unable to meet the LIMIT criteria.
(ref).
Time overlap across consecutive files adds a bit of complexity to this. To handle it, they create sub-plans for each batch of contiguous files with overlapping and non-overlapping data. For non-overlapping data they leverage ProgressiveEval, and for overlapping they continue using Dedup and SortMerge.
You can see an example plan below, which is shared in this blog.
ProgressiveEvalExec: fetch=1
SortExec: TopK(fetch=1), expr=[time DESC], preserve_partitioning=[false]
DeduplicateExec:
SortPreservingMergeExec:
SortExec:
RecordBatchExec: {C}
ParquetExec: file_groups={2 groups: [F8], [F9]}
SortExec: TopK(fetch=1), expr=[time DESC], preserve_partitioning=[true]
ParquetExec: file_groups={2 groups: [F7], [F6]}
SortExec: TopK(fetch=1), expr=[time DESC], preserve_partitioning=[false]
DeduplicateExec:
SortPreservingMergeExec:
ParquetExec: file_groups={3 groups: [F4], [F3], [F5]}
SortExec: TopK(fetch=1), expr=[time DESC], preserve_partitioning=[true]
ParquetExec: file_groups={2 groups: [F2], [F1]}
Digression: I think one could also leverage something like a Line Sweep to run the per-file operator chains in sequence. Once the limit threshold is reached and the “open interval count” reaches zero, the processing could terminate.
Scattered Takeaways from the Recent CMU Talk
In his recent CMU DB Talk, Paul Dix from Influx mentioned that Cloud SSD Performance is bad and alluded to some past discussion regarding it in the Database community. I think he might be referring to this blog on the same from back in Feb’2024. There was also a HN Post related to this, but I don’t see any conclusion or takeaway in it.
Another point Paul raised was that FlightSQL is not great for usability. People generally prefer HTTP/JSON, and it’s hard to work around that.
Finally, he mentioned that InfluxDB Parquet files aren’t readable by third party vendors. To make Parquet readable by a multitude of systems usually means that you have to look at a very minimal set of features, which doesn’t work out when you are trying to maximize performance.
References
As part of researching this I went through all of Influx’s Engineering Blogs released in the last 1 year. I also went through their recent CMU DB talk a couple of times, which I would highly recommend you to check out.
This is a custom-built theme for Jekyll. Please report any issues on GitHub.